Understanding the Pipeline
Every container in Iron Bank utilizes the Container Hardening pipeline. At a high level, the pipeline is responsible for the following:
- Ensure compliance with CHT project structure guidelines and check for the presence of required files.
- Retrieve the resources used in the container build process and build the hardened container.
- Perform scans of the container in order to evaluate for security vulnerabilities.
- Publish scan findings to the VAT (Vulerability Assessment Tracking tool) and the hardened container to Registry1.
Pipeline Documentation
This page provides an overview of the pipeline and includes information which may be helpful in getting started with the pipeline when onboarding. For in-depth information on the pipeline, including specific stage writeups and to view the code, please access the Iron Bank Pipeline Documentation.
Getting Started
The first thing you need to know when onboarding is which Iron Bank base image you want to use. The container hardening pipeline behaves slightly different for each base image. The pipeline builds the image regardless of which Iron Bank image you use. Check out the guide for Choosing a Base Image.
The pipeline can operate in standard mode or Verified Publisher mode.
-
Standard mode (default)
- The vendor provides Dockerfile and pipeline builds image.
- This mode is available to all vendors.
-
Verified Publisher (VP) mode
- The vendor provides image(s) from their image registry.
- The pipeline pulls image and scans the image from the Vendor's image registry; no build occurs.
- Approved vendors are eliglible for this pipline mode.
- Documenation on Verified Publisher Program: Verified Publisher Program
Early in the pipeline a linting stage occurs which enforces the correct repository structure and verifies the presence of required files. This stage is run in order to ensure compliance with Container Hardening team requirements. Please ensure that your repository structure meets the guidelines provided by the Container Hardening team and that all the necessary files exist, otherwise the Container Hardening pipeline will fail as a result.
Artifacts
The Container Hardening pipeline utilizes GitLab CI/CD artifacts in order to run stages which are dependent on previous stage(s) resources and to provide Repo1 contributors with access to the artifacts produced by the pipeline which are relevant to them. For example these artifacts can include a tar file of the built image, or a scan results file which contributors can use to enter justifications for any security findings.
For more information regarding specific artifacts for each stage, please refer to the following documentation from the Container Hardening pipeline project.
Project Branches
The Container Hardening pipeline runs slightly differently depending on the hardened container project branch it is run on. The reason for this is to ensure a proper review of the repository content before the code is merged into a development branch or master branch, which publish items to production systems.
| Branch | Pipeline actions |
|---|---|
| Feature branches | Does not publish images to public Registry1 or findings results to the Iron Bank. |
development |
Does not publish images to public Registry1 or findings results to the Iron Bank. Merging is required to be performed by the Container Hardening Team, but you can open the merge request. |
master |
Publishes images to public Registry1 and findings results to the Iron Bank. Merging is required to be performed by the Container Hardening Team, but you can open the merge request. |
Pipeline Stages
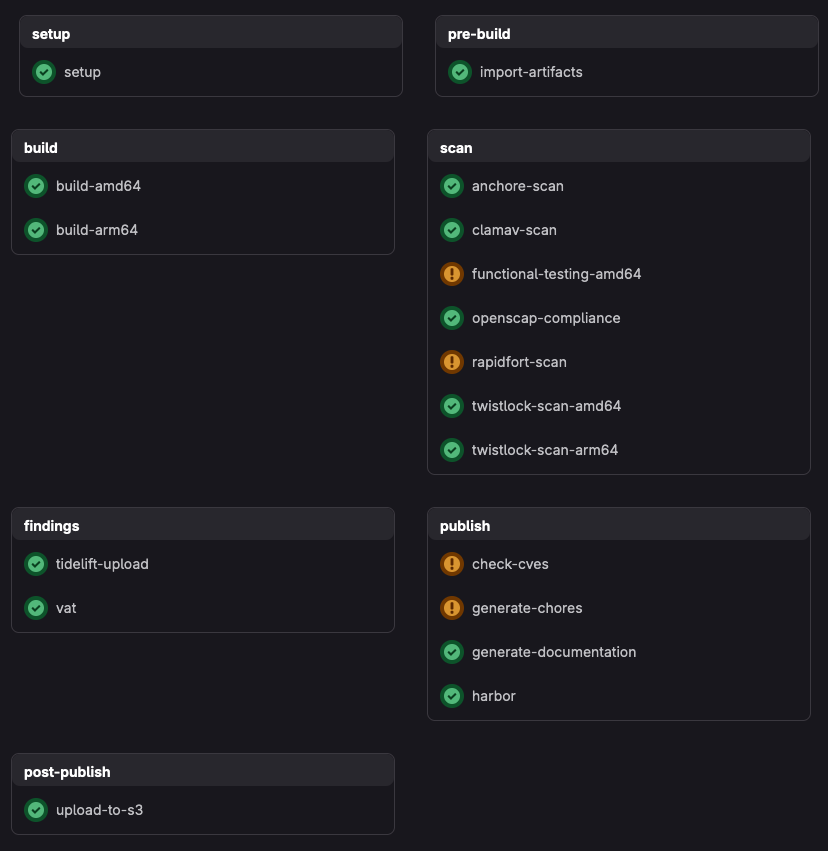
setup / setup
This preliminary stage sets up the workspace and verifies the presence and validity of required files and directories in the repository.
As part of the setup stage, the pipeline utilizes Semgrep to statically analyze Dockerfile and Dockerfile.arm64 files against a set of curated linting rules. Semgrep provides flexibility and ongoing support, ensuring modern Dockerfile best practices are enforced.
The scan is performed using custom rules located at pipeline1/0-setup/semgrep-dockerfile-lint/semgrep-dockerfile-rules.yaml. Any issues found are logged to the job output and will raise warnings during the pipeline execution. These warnings will be visible in the job logs and can be used to address structural or security concerns early in the build process. Note that findings resulting from a scan will not fail the pipeline.
pre-build / import-artifacts
This stage imports any external resources (resources from the internet) listed in the hardening_manifest.yaml file for use during the hardened image build. It downloads the external resources and validates the resource's checksums calculated upon download match the checksums provided in the hardening_manifest.yaml file.
build / build-amd64
The container build process takes place in an offline environment.
The only resources the build environment has access to are the resources listed in the project's hardening_manifest.yaml, images from Registry1, and the following proxied package managers:
- Pypi, for Python based containers using the
pippackage manager, - Golang proxy for go based containers.
- npm for Node.js images.
- Rubygems for Ruby projects that use
gemandbundler.
Any attempts to reach out to the internet will be rejected by the cluster's egress policy and the build stage will fail.
Additionally, the build job also makes use of Anchore's syft product to generate spdx, CycloneDX, and syft JSON SBOM reports. For more insight into the build stage, please refer to the following documentation from the Container Hardening pipeline project.
build / build-arm64 (optional)
This job builds an arm64 image. It requires the presence of a Dockerfile.arm64 in the project to be generated by the pipeline.
It is configured to work the same way as the build-amd64 job, and builds in the same offline context.
scan stage overview
These scans run to ensure any vulnerabilities in the image are accounted for (such as dependency security flags). The scan results are generated so an auditor can manually review potential security flags raised in the scan.
Should the auditor determine the scan results are satisfactory, the container(s) will be published to Iron Bank.
The scan stage also contains optional jobs enabling testing the container.
The pipeline begins by pulling the container image from Repo One, and proceeds to run a series of scans on the container:
scan / anchore-scan
The anchore-scan job runs vulnerability, compliance, and scans.
Please contact Anchore directly for an enterprise license or more information. You can visit the Anchore documentation to get started and learn more.
NOTE: To optionally include additional compliance rules, set any combination of these CI/CD variables in your container repository to a non-empty string:
ENABLE_REPORT_FEDRAMP- Scan against FedRAMP policiesENABLE_REPORT_CIS- Scan against CIS policiesENABLE_REPORT_NIST- Scan against NIST (800-53, 800-190) policies
scan / clamav-scan
The clamav-scan job runs an anti-virus/anti-malware scan performed by the open source tool ClamAV.
ClamAV has a database of viruses and malware which is updated daily.
scan / create-tar (optional)
The create-tar job outputs a Docker archive of the image as a tarball.
This tarball can be downloaded, and run locally to test the built image.
docker load -i <path-to-archive>
This job is only created if ENABLE_TAR CI variable is set to a non-empty string.
scan / clamav-scan
The clamav-scan job runs an anti-virus/anti-malware scan performed by the open source tool ClamAV.
ClamAV has a database of viruses and malware which is updated daily.
scan / create-tar (optional)
The create-tar job outputs a Docker archive of the image as a tarball.
This tarball can be downloaded, and run locally to test the built image.
docker load -i <path-to-archive>
This job is only created if ENABLE_TAR CI variable is set to a non-empty string.
scan / openscap-compliance
The openscap-compliance job runs ab OpenSCAP Compliance scan which enables us to provide configuration scans on container images.
The openscap-compliance job runs ab OpenSCAP Compliance scan which enables us to provide configuration scans on container images.
The particular security profiles that we use to scan container images conforms to the DISA STIG for Red Hat Enterprise Linux 8 and 9.
scan / rapidfort-scan (optional)
The rapidfort-scan job runs a vulnerability scan and generates an RBOM (RapidFort's Real Bill of Materials).
This job is only created if ENABLE_RF CI variable is set to a non-empty string.
Please visit RapidFort for more information.
scan / twistlock-scan-amd64/arm64
The twistlock scan checks container images for vulnerabilities. Please visit paloalto networks for more information.
scan / functional-testing-amd64/arm64 (optional)
The functional-testing job starts a container with the built image and runs command with it. The output can be checked against an expected output.
Please visit this functional-testing blog post for more information.
scan / functional-testing-amd64/arm64-fips (optional)
The functional-testing job starts a container on a FIPs enabled host with the built image and runs command with it. The output can be checked against an expected output.
Please visit this functional-testing blog post for more information.
findings / tidelift-upload (optional)
The tidelift-upload job uploads the SBOM to TideLift for analysis and then outputs a vulnerability report based on the findings.
This job is only created if ENABLE_TIDELIFT CI variable is set to a non-empty string.
Please visit TideLift for more information.
findings / vat
The VAT stage uses pipeline artifacts from the scan stage jobs to populate the Vulnerability Assessment Tracker (VAT) at vat.dso.mil.
Users who maintain the hardening of an image use VAT to track the known findings for an image, and provide justifications for findings that are not able to be mitigated.
The VAT also calculates the Acceptance Baseline Criteria (ABC) status and Overall Risk Assessment (ORA) score.
publish / check-cves
This stage utilizes the API response artifact from the VAT stage, to log all findings which have not been justified or reviewed. With the release of the ABC/ORA, this job is now for informational purposes, to alert project maintainers to new or unjustified vulnerabilities.
publish / Updating Staging Attestions
Images built from the development and feature branches do not have their VAT predicate attestations uploaded by default. But there are cases where you do want to use an image from staging (which are built from development and feature-branches) as your base parent image. The pipeline will fail because vat attestation predicates from the parent image are needed for an accurate attestation chain of the child image.
To enable using a staging parent image:
Run the parent image pipeline on the protected non-master branch with the PUBLISH_VAT_STAGING_PREDICATES CI variable set to "True".
Note that only maintainers of a project can make a branch protected.
When that pipeline completes, run the child image pipeline with STAGING_BASE_IMAGE CI variable set to "True". You child pipeline will now be able to pass the VAT stage because it can download the vat attestations of the parent image.
Master branch only jobs
Info
As mentioned above, the following stages of the pipeline will only run on master branches.
publish / generate-chores
This job creates and maintains a chore ticket (gitlab issue) when uninherited + unjustified findings exist; also, Tidelift's SBOM scans may report novel findings in the chore ticket.
This job is only created if the tidelift-upload job was ran.
publish / generate-documentation
The generate-documentation job generates CSV files for the various scans, and justifications spreadsheet.
The generated files can be found in the artifacts for this job.
Members of the Container Hardening team, vendors, and contributors use the justifications spreadsheet as the list of findings for the container they are working on.
This job also generates the generates the json documentation and scan results documentation which is made available through the job's artifacts.
publish / harbor
Pushes built images, SBOM files, and VAT response file as an attestation, to registry1.dso.mil/ironbank.
The image and SBOM attachment are signed using cosign. A signed manifest-list is created in harbor which allows the pipeline to support multi-arch images.
See the ironbank-pipeline cosign documentation for instructions on how to perform image validation, and download .sbom, .att, and .sig artifacts.
The image and SBOM attachment are signed using cosign. A signed manifest-list is created in harbor which allows the pipeline to support multi-arch images.
See the ironbank-pipeline cosign documentation for instructions on how to perform image validation, and download .sbom, .att, and .sig artifacts.
post-publish / upload-to-s3
This job uploads documentation artifacts to S3, which are displayed/utilized by the Iron Bank website (e.g. scan reports, project README, project LICENSE).